
Prisma Schema
Prisma Schema
概述
Prisma 模式文件(简称:模式文件、Prisma 模式或模式)是 Prisma ORM 设置的主要配置文件。它通常称为 schema.prisma,包含以下部分
- 数据源: 指定 Prisma ORM 应连接到的数据源的详细信息(例如 PostgreSQL 数据库)
- 生成器: 指定应根据数据模型生成哪些客户端(例如 Prisma Client)
- 数据模型定义: 指定应用程序的 模型(每个数据源的数据形状)及其 关系
有关模式每个部分的详细信息,请参阅 Prisma 模式 API 参考 。
每当调用 prisma 命令时,CLI 通常会从模式文件中读取一些信息,例如:
prisma generate: 从 Prisma 模式中读取所有上述信息,以生成正确的数据源客户端代码(例如 Prisma Client)。prisma migrate dev: 读取数据源和数据模型定义以创建新的迁移。
您还可以 在模式文件中使用环境变量,以便在调用 CLI 命令时提供配置选项。
datasource
数据源决定了 Prisma ORM 如何连接你的数据库,并由 Prisma 架构中的 datasource 块表示。以下数据源使用 postgresql 提供程序并包含一个连接 URL
datasource db {
provider = "postgresql"
url = "postgresql://johndoe:mypassword@localhost:5432/mydb?schema=public"
}一个 Prisma 架构只能有一个数据源。
generator
Prisma 架构可以有一个或多个生成器,由 generator 块表示
generator client {
provider = "prisma-client-js"
output = "./generated/prisma-client-js"
}生成器决定在你运行 prisma generate 命令时创建哪些资产。主要属性 provider 定义创建哪个 Prisma Client(特定语言) - 目前,仅提供 prisma-client-js。或者,你可以定义遵循我们生成器规范的任何 npm 包。此外,你还可以使用 output 为生成的资产定义一个自定义输出文件夹。
Prisma Client:prisma-client-js
Prisma JavaScript Client 的生成器接受多个附加属性
previewFeatures:要包含的 预览功能binaryTargets:prisma-client-js的引擎二进制目标(例如,如果你部署到 Ubuntu 18+,则为debian-openssl-1.1.x;如果你在本地工作,则为native)
generator client {
provider = "prisma-client-js"
previewFeatures = ["sample-preview-feature"]
binaryTargets = ["linux-musl"]
}Schema location
Prisma 架构的默认名称是prisma文件夹中的单个文件schema.prisma 。当您的模式如此命名时,Prisma CLI 将自动检测它
由--schema标志指定的位置,当您introspect 、 generate 、 migrate和studio时可用:
prisma generate --schema=./alternative/schema.prisma或者package.json文件中指定的位置(2.7.0 及更高版本):
"prisma": {
"schema": "db/schema.prisma"
}Default locations: 默认位置:
./prisma/schema.prisma./schema.prisma
多文件 Prisma
要使用多个 Prisma 架构文件,请在当前prisma目录中添加一个schema文件夹。启用prismaSchemaFolder预览功能后,您可以将任意数量的文件添加到prisma/schema目录中。
my-app/
├─ ...
├─ prisma/
│ ├─ schema/
│ │ ├─ post.prisma
│ │ ├─ schema.prisma
│ │ ├─ user.prisma
├─ ...如何启用多文件 Prisma 架构
对多个 Prisma Schema 文件的支持当前处于预览阶段。要启用该功能,请将prismaSchemaFolder功能标志添加到 Prisma 架构中generator块的previewFeatures字段中:
generator client {
provider = "prisma-client-js"
previewFeatures = ["prismaSchemaFolder"]
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}如何将现有 Prisma CLI 命令与多个 Prisma 架构文件结合使用
对于大多数 Prisma CLI 命令,无需进行任何更改即可使用多文件 Prisma 架构。仅在需要通过选项提供模式的特定情况下才需要更改命令。在这些情况下,只需用目录替换对文件的引用即可。例如,以下prisma db push命令:
npx prisma db push --schema custom/path/to/my/schema.prisma提示
拥有一个明显的“主”模式文件:虽然您现在可以拥有任意数量的模式文件,但您仍然需要一个定义datasource和generator块的位置。我们建议使用一个显然是“主”文件的模式文件,以便可以轻松找到这些块。 main.prisma 、 schema.prisma和base.prisma是我们见过的运行良好的几个。
Model
Prisma 架构 的数据模型定义部分定义了应用程序模型(也称为Prisma 模型)。模型
- 表示应用程序域的实体
- 映射到数据库中的表(关系型数据库,如 PostgreSQL)或集合(MongoDB)
- 形成生成的Prisma 客户端 API 中可用查询的基础
- 与 TypeScript 配合使用时,Prisma 客户端为模型提供生成的类型定义,以及它们的任何变体,以使数据库访问完全类型安全。
以下架构描述了一个博客平台
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
generator client {
provider = "prisma-client-js"
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
role Role @default(USER)
posts Post[]
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
bio String
user User @relation(fields: [userId], references: [id])
userId Int @unique
}
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
updatedAt DateTime @updatedAt
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
categories Category[]
}
model Category {
id Int @id @default(autoincrement())
name String
posts Post[]
}
enum Role {
USER
ADMIN
}数据模型定义由以下内容组成
以下查询使用从该数据模型生成的 Prisma Client 来创建
- 一个
User记录 - 两个嵌套的
Post记录 - 三个嵌套的
Category记录
const user = await prisma.user.create({
data: {
email: 'ariadne@prisma.io',
name: 'Ariadne',
posts: {
create: [
{
title: 'My first day at Prisma',
categories: {
create: {
name: 'Office',
},
},
},
{
title: 'How to connect to a SQLite database',
categories: {
create: [{ name: 'Databases' }, { name: 'Tutorials' }],
},
},
],
},
},
})内省和迁移
有两种方法可以定义数据模型
- 手动编写数据模型并使用 Prisma Migrate:您可以手动编写数据模型,并使用 Prisma Migrate 将其映射到数据库。在这种情况下,数据模型是应用程序模型的唯一真实来源。
- 通过内省生成数据模型:如果您有现有的数据库或更喜欢使用 SQL 迁移数据库架构,则可以通过 内省 数据库来生成数据模型。在这种情况下,数据库架构是应用程序模型的唯一真实来源。
定义模型
模型表示应用程序域的实体。模型由 model 块表示,并定义了许多 字段。在上面的示例数据模型中,User、Profile、Post 和 Category 是模型。
博客平台可以通过以下模型进行扩展
model Comment {
// Fields
}
model Tag {
// Fields
}将模型名称映射到表或集合
Prisma 模型 命名约定(单数形式,PascalCase) 并不总是与数据库中的表名称相匹配。在数据库中命名表/集合的常见方法是使用复数形式和 snake_case 表示法 - 例如:comments。当您内省一个名为 comments 的表的数据库时,结果 Prisma 模型将如下所示
model comments {
// Fields
}但是,您仍然可以使用 @@map 属性来遵守命名约定,而无需重命名数据库中基础的 comments 表
model Comment {
// Fields
@@map("comments")
}使用此模型定义,Prisma ORM 会自动将 Comment 模型映射到基础数据库中的 comments 表。
注意:您还可以
@map列名或枚举值,并@@map枚举名。
@map 和 @@map 允许您 调整 Prisma Client API 的形状,方法是从基础数据库中解耦模型和字段名称以及表和列名称。
定义字段
标量字段
以下示例使用多个标量类型扩展了 Comment 和 Tag 模型。某些字段包括 属性
model Comment {
id Int @id @default(autoincrement())
title String
content String
}
model Tag {
name String @id
}请参阅 标量字段类型的完整列表。
关系字段
关系字段的类型是另一个模型 - 例如,一个帖子(Post)可以有多个评论(Comment[])
model Post {
comments Comment[] // A post can have many comments
}
model Comment {
// Other fields
post Post? @relation(fields: [postId], references: [id]) // A comment can have one post
}有关模型之间关系的更多示例和信息,请参阅 关系文档。
本机类型映射
model Post {
title String @db.VarChar(200)
}类型属性是
- 特定于底层提供程序 - 例如,PostgreSQL 使用
@db.Boolean表示Boolean,而 MySQL 使用@db.TinyInt(1) - 以 PascalCase 编写(例如,
VarChar或Text) - 以
@db为前缀,其中db是架构中datasource块的名称
此外,在 自省 期间,仅当底层本机类型不是默认类型时,才会将类型属性添加到架构中。例如,如果你正在使用 PostgreSQL 提供程序,底层本机类型为 text 的 String 字段将没有类型属性。
请参阅 每个标量类型和提供程序的本机数据库类型属性的完整列表。
类型修饰符
可以通过附加两个修饰符中的任何一个来修改字段的类型
注意:不能组合类型修饰符 - 不支持可选列表。
model Post {
id Int @id @default(autoincrement())
// Other fields
comments Comment[] // A list of comments
keywords String[] // A scalar list
}
model Comment {
id Int @id @default(autoincrement())
title String
content String?
}
model Tag {
name String @id
}不使用?类型修饰符对字段进行注释时,该字段在模型的每条记录中都是必需的。这在两个级别上都有影响
- 数据库
- 关系数据库:必需字段通过底层数据库中的
NOT NULL约束表示。 - MongoDB:必需字段不是 MongoDB 数据库级别上的概念。
- 关系数据库:必需字段通过底层数据库中的
- Prisma Client:Prisma Client 生成的TypeScript 类型表示应用程序代码中的模型,也将定义这些字段为必需字段,以确保它们在运行时始终带有值。
注意:可选字段的默认值为
null。
定义属性
属性修改字段或模型块的行为。以下示例包括三个字段属性(@id、@default 和 @unique)和一个块属性(@@unique)
model User {
id Int @id @default(autoincrement())
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@unique([firstName, lastName])
}复合 ID
model User {
firstName String
lastName String
email String @unique
isAdmin Boolean @default(false)
@@id(name: "fullName", fields: [firstName, lastName])
}定义默认值
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
categories Category[] @relation(references: [id])
}@default 属性
- 表示底层数据库中的
DEFAULT值(仅限关系数据库)或 - 使用 Prisma ORM 级别函数。例如,
cuid()和uuid()由 Prisma Client 的 查询引擎 为所有连接器提供。
默认值可以是
- 对应于字段类型的静态值,例如
5(Int)、Hello(String)或false(Boolean) - 列表的静态值,例如
[5, 6, 8](Int[])或["Hello", "Goodbye"](String[])。当使用受支持的数据库(PostgreSQL、CockroachDB 和 MongoDB)时,这些值在 Prisma ORM 版本4.0.0及更高版本中可用 - 函数,例如
now()或uuid()
定义唯一字段
model Post {
id String @id @default(auto()) @map("_id") @db.ObjectId
createdAt DateTime @default(now())
title String
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId String @db.ObjectId
categories Category[] @relation(references: [id])
@@unique(name: "authorTitle", [authorId, title])
}定义索引
model Post {
id Int @id @default(autoincrement())
title String
content String?
@@index([title, content])
}定义枚举
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
role Role @default(USER)
}
enum Role {
USER
ADMIN
}使用函数
model Post {
id Int @id @default(autoincrement())
createdAt DateTime @default(now())
}cuid() 和 uuid() 由 Prisma ORM 实现,因此在底层数据库模式中“不可见”。在使用 内省 时,你仍然可以使用它们,方法是 手动更改 Prisma 模式 并 生成 Prisma Client,在这种情况下,值将由 Prisma Client 的 查询引擎 生成
对 autoincrement()、now() 和 dbgenerated() 的支持因数据库而异。
关系
关系是 Prisma 架构中两个模型之间的连接。例如,User 和 Post 之间存在一对多关系,因为一个用户可以拥有多个博客文章。
以下 Prisma 架构定义了 User 和 Post 模型之间的一对多关系。定义关系的字段已突出显示
model User {
id Int @id @default(autoincrement())
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
author User @relation(fields: [authorId], references: [id])
authorId Int // relation scalar field (used in the `@relation` attribute above)
}在 Prisma ORM 级别,User / Post 关系由以下组成
- 两个 关系字段:
author和posts。关系字段定义了 Prisma ORM 级别模型之间的连接,并且在数据库中不存在。这些字段用于生成 Prisma 客户端。 - 标量
authorId字段,由@relation属性引用。此字段在数据库中存在 - 它是连接Post和User的外键。
在 Prisma ORM 级别,两个模型之间的连接始终由 关系字段 表示,位于关系的每一侧。
关系型数据库
在 SQL 中,使用外键来创建两个表之间的关系。外键存储在关系的一侧。我们的示例由以下组成
Post表中的名为authorId的外键列。User表中的名为id的主键列。Post表中的authorId列引用User表中的id列。
在 Prisma 架构中,外键/主键关系由author字段上的@relation属性表示
author User @relation(fields: [authorId], references: [id])注意:Prisma 架构中的关系表示数据库中的表之间存在的关系。如果关系不存在于数据库中,则它不存在于 Prisma 架构中。
Prisma Client 中的关系
创建记录和嵌套记录
以下查询创建了一个User记录和两个连接的Post记录
const userAndPosts = await prisma.user.create({
data: {
posts: {
create: [
{ title: 'Prisma Day 2020' }, // Populates authorId with user's id
{ title: 'How to write a Prisma schema' }, // Populates authorId with user's id
],
},
},
})在底层数据库中,此查询
- 使用自动生成的
id(例如,20)创建User - 创建两条新的
Post记录,并将两条记录的authorId设置为20
检索记录并包含相关记录
以下查询通过 id 检索 User,并包含任何相关的 Post 记录
const getAuthor = await prisma.user.findUnique({
where: {
id: "20",
},
include: {
| posts: true, // All posts where authorId == 20
},
});在底层数据库中,此查询
- 检索
id为20的User记录 - 检索
authorId为20的所有Post记录
将现有记录与另一个现有记录关联
以下查询将现有 Post 记录与现有 User 记录关联
const updateAuthor = await prisma.user.update({
where: {
id: 20,
},
data: {
posts: {
connect: {
id: 4,
},
},
},
})在底层数据库中,此查询使用 嵌套 connect 查询 将 id 为 4 的帖子与 id 为 20 的用户链接起来。查询通过以下步骤完成此操作
- 查询首先查找
id为20的用户。 - 然后,查询将
authorID外键设置为20。这将id为4的帖子与id为20的用户链接起来。
在此查询中,authorID 的当前值无关紧要。查询将 authorID 更改为 20,无论其当前值如何。
关系类型
Prisma ORM 中有三种不同的关系类型(或 基数)
以下 Prisma 架构包括每种类型的关系
- 一对一:
User↔Profile - 一对多:
User↔Post - 多对多:
Post↔Category
model User {
id Int @id @default(autoincrement())
posts Post[]
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userId], references: [id])
userId Int @unique // relation scalar field (used in the `@relation` attribute above)
}
model Post {
id Int @id @default(autoincrement())
author User @relation(fields: [authorId], references: [id])
authorId Int // relation scalar field (used in the `@relation` attribute above)
categories Category[]
}
model Category {
id Int @id @default(autoincrement())
posts Post[]
}对于关系数据库,以下实体关系图表示与示例 Prisma 架构相对应的数据库
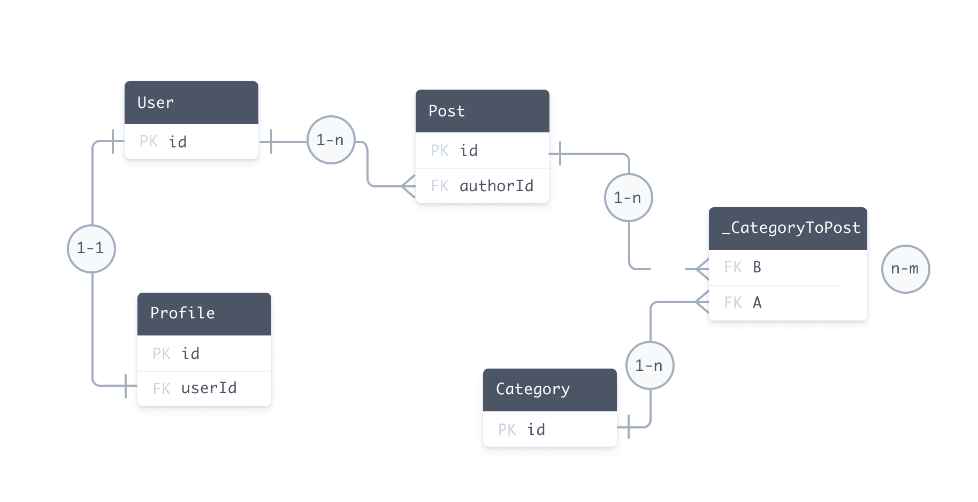
隐式和显式多对多关系
关系型数据库中的多对多关系可以用两种方式建模
隐式多对多关系要求两个模型都有一个 @id。请注意以下事项
- 您不能使用 多字段 ID
- 您不能使用
@unique代替@id
要使用其中任何一个功能,您必须设置显式多对多关系。
隐式多对多关系仍然在底层数据库中的关系表中体现。但是,Prisma ORM 管理此关系表。
如果您使用隐式多对多关系而不是显式关系,它会使 Prisma Client API 变得更简单(例如,因为您在 嵌套写入 中的嵌套级别减少了一级)。
如果您不使用 Prisma Migrate,而是从 内省 获取数据模型,则仍然可以通过遵循 Prisma ORM 的 隐式多对多关系中的关系表约定 来利用隐式多对多关系。
关系字段
关系 字段 是 Prisma 模型 上的字段,它们没有 标量类型。相反,它们的类型是另一个模型。
每个关系必须恰好有两个关系字段,每个模型上一个。对于一对一和一对多关系,需要一个额外的关系标量字段,该字段通过 @relation 属性中的两个关系字段之一进行链接。此关系标量是底层数据库中外键的直接表示。
model User {
id Int @id @default(autoincrement())
email String @unique
role Role @default(USER)
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
author User @relation(fields: [authorId], references: [id])
authorId Int // relation scalar field (used in the `@relation` attribute above)
}posts 和 author 都是关系字段,因为它们的类型不是标量类型,而是其他模型。
另请注意,带注释的关系字段 author 需要在 @relation 属性中链接 Post 模型上的关系标量字段 authorId。关系标量表示底层数据库中的外键。
另一个称为 posts 的关系字段纯粹在 Prisma ORM 级别定义,它不会在数据库中体现。
带注释的关系字段
需要关系的一方使用 @relation 属性进行注释的关系称为带注释的关系字段。这包括
- 一对一关系
- 一对多关系
- 仅适用于 MongoDB 的多对多关系
使用 @relation 属性进行注释的关系的一方表示存储底层数据库中外键的一方。表示外键的“实际”字段也在关系的那一方是必需的,它称为关系标量字段,并在 @relation 属性中引用
author User @relation(fields: [authorId], references: [id])
authorId Int@relation 属性
@relation 属性只能应用于关系字段,不能应用于标量字段。
在以下情况下,@relation 属性是必需的
- 定义一对一或一对多关系时,它在关系的一侧(具有相应的标量关系字段)是必需的
- 需要消除关系的歧义(例如,当在同一模型之间有两个关系时)
- 定义自关系时
- 需要控制关系表在底层数据库中的表示方式(例如,为关系表使用特定名称)时
注意:关系数据库中的隐式多对多关系不需要
@relation属性。
消除关系歧义
在同一两个模型之间定义两个关系时,需要在 @relation 属性中添加 name 参数以消除歧义。例如,考虑以下模型
model User {
id Int @id @default(autoincrement())
name String?
writtenPosts Post[]
pinnedPost Post?
}
model Post {
id Int @id @default(autoincrement())
title String?
author User @relation(fields: [authorId], references: [id])
authorId Int
pinnedBy User? @relation(fields: [pinnedById], references: [id])
pinnedById Int?
}在这种情况下,关系是模棱两可的,有四种不同的解释方式
User.writtenPosts↔Post.author+Post.authorIdUser.writtenPosts↔Post.pinnedBy+Post.pinnedByIdUser.pinnedPost↔Post.author+Post.authorIdUser.pinnedPost↔Post.pinnedBy+Post.pinnedById
若要消除这些关系的歧义,你需要使用 @relation 属性注释关系字段并提供 name 参数。你可以设置任何 name(空字符串 "" 除外),但关系两边必须相同
model User {
id Int @id @default(autoincrement())
name String?
writtenPosts Post[] @relation("WrittenPosts")
pinnedPost Post? @relation("PinnedPost")
}
model Post {
id Int @id @default(autoincrement())
title String?
author User @relation("WrittenPosts", fields: [authorId], references: [id])
authorId Int
pinnedBy User? @relation("PinnedPost", fields: [pinnedById], references: [id])
pinnedById Int? @unique
}一对一关系
一对一 (1-1) 关系是指关系中最多一个记录可以在关系的两边连接。在下面的示例中,User 和 Profile 之间存在一对一关系
model User {
id Int @id @default(autoincrement())
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userId], references: [id])
userId Int @unique // relation scalar field (used in the `@relation` attribute above)
}userId 关系标量是底层数据库中外键的直接表示。此一对一关系表示以下内容
- "一个用户可以没有个人资料或一个个人资料"(因为
profile字段在User上是可选的) - "个人资料必须始终连接到一个用户"
在前面的示例中,Profile 模型的 user 关系字段引用 User 模型的 id 字段。您还可以引用不同的字段。在这种情况下,您需要使用 @unique 属性标记该字段,以确保只有一个 User 连接到每个 Profile。在以下示例中,user 字段引用 User 模型中的 email 字段,该字段已使用 @unique 属性标记
model User {
id Int @id @default(autoincrement())
email String @unique // <-- add unique attribute
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userEmail], references: [email])
userEmail String @unique // relation scalar field (used in the `@relation` attribute above)
}关系数据库中的多字段关联
在仅关系数据库中,你还可以使用 多字段 ID 来定义 1-1 关联
model User {
firstName String
lastName String
profile Profile?
@@id([firstName, lastName])
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userFirstName, userLastName], references: [firstName, lastName])
userFirstName String // relation scalar field (used in the `@relation` attribute above)
userLastName String // relation scalar field (used in the `@relation` attribute above)
@@unique([userFirstName, userLastName])
}选择在 1-1 关系中哪一方应存储外键
在1-1 关系中,你可以自行决定使用 @relation 属性注释关系的哪一方(因此持有外键)。
在以下示例中,Profile 模型上的关系字段使用 @relation 属性进行注释。userId 是底层数据库中外键的直接表示
model User {
id Int @id @default(autoincrement())
profile Profile?
}
model Profile {
id Int @id @default(autoincrement())
user User @relation(fields: [userId], references: [id])
userId Int @unique // relation scalar field (used in the `@relation` attribute above)
}一对多关系
一对多 (1-n) 关系是指关系一侧的一条记录可以连接到关系另一侧的零条或多条记录。在以下示例中,User 和 Post 模型之间有一个一对多关系
model User {
id Int @id @default(autoincrement())
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
author User @relation(fields: [authorId], references: [id])
authorId Int
}此一对多关系表示以下内容
- “一个用户可以有零条或多条帖子”
- “一条帖子必须始终有一个作者”
在前面的示例中,Post 模型的 author 关系字段引用 User 模型的 id 字段。你还可以引用其他字段。在这种情况下,你需要用 @unique 属性标记该字段,以确保只有单个 User 连接到每个 Post。在以下示例中,author 字段引用 User 模型中的 email 字段,该字段已用 @unique 属性标记
model User {
id Int @id @default(autoincrement())
email String @unique // <-- add unique attribute
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
authorEmail String
author User @relation(fields: [authorEmail], references: [email])
}多对多关系
在关系型数据库中,m-n 关系通常通过 关系表 建模。m-n 关系在 Prisma 架构中可以是 显式的 或 隐式的。如果您不需要在关系表本身中存储任何其他元数据,我们建议使用 隐式的 m-n 关系。如果需要,您始终可以稍后迁移到 显式的 m-n 关系。
显式的多对多关系
在显式的 m-n 关系中,关系表在 Prisma 架构中表示为一个模型,并且可以在查询中使用。显式的 m-n 关系定义了三个模型
- 两个具有 m-n 关系的模型,例如
Category和Post。 - 一个表示 关系表 的模型,例如底层数据库中的
CategoriesOnPosts(有时也称为联接、链接或枢纽表)。关系表模型的字段都是带对应关系标量字段(postId和categoryId)的标注关系字段(post和category)。
关系表 CategoriesOnPosts 连接相关的 Post 和 Category 记录。在此示例中,表示关系表的模型还定义了附加字段,这些字段描述了 Post/Category 关系 - 谁分配了类别 (assignedBy) 以及何时分配了类别 (assignedAt)
model Post {
id Int @id @default(autoincrement())
title String
categories CategoriesOnPosts[]
}
model Category {
id Int @id @default(autoincrement())
name String
posts CategoriesOnPosts[]
}
model CategoriesOnPosts {
post Post @relation(fields: [postId], references: [id])
postId Int // relation scalar field (used in the `@relation` attribute above)
category Category @relation(fields: [categoryId], references: [id])
categoryId Int // relation scalar field (used in the `@relation` attribute above)
assignedAt DateTime @default(now())
assignedBy String
@@id([postId, categoryId])
}请注意,与 1-n 关系 相同的规则适用(因为 Post↔ CategoriesOnPosts 和 Category ↔ CategoriesOnPosts 实际上都是 1-n 关系),这意味着关系的一方需要用 @relation 属性进行注释。
当不需要将附加信息附加到关系时,可以将 m-n 关系建模为 隐式 m-n 关系。如果不使用 Prisma Migrate,而是从 内省获取数据模型,则仍可以通过遵循 Prisma ORM 的 隐式 m-n 关系中的关系表约定 来利用隐式 m-n 关系。
查询显式多对多
以下部分演示如何查询显式 m-n 关系。可以直接查询关系模型 (prisma.categoriesOnPosts(...)),或使用嵌套查询从 Post -> CategoriesOnPosts -> Category 或其他方式进行查询。
以下查询执行三个操作
- 创建
Post - 在关系表
CategoriesOnPosts中创建新记录 - 创建与新创建的
Post记录关联的新Category
const createCategory = await prisma.post.create({
data: {
title: 'How to be Bob',
categories: {
create: [
{
assignedBy: 'Bob',
assignedAt: new Date(),
category: {
create: {
name: 'New category',
},
},
},
],
},
},
})以下查询
- 创建新
Post - 在关系表
CategoriesOnPosts中创建新记录 - 将类别分配连接到现有类别(ID 为
9和22)
const assignCategories = await prisma.post.create({
data: {
title: 'How to be Bob',
categories: {
create: [
{
assignedBy: 'Bob',
assignedAt: new Date(),
category: {
connect: {
id: 9,
},
},
},
{
assignedBy: 'Bob',
assignedAt: new Date(),
category: {
connect: {
id: 22,
},
},
},
],
},
},
})有时你可能不知道 Category 记录是否存在。如果 Category 记录存在,则希望将新 Post 记录连接到该类别。如果 Category 记录不存在,则希望先创建记录,然后将其连接到新 Post 记录。以下查询
- 创建新
Post - 在关系表
CategoriesOnPosts中创建新记录 - 将类别分配连接到现有类别(ID 为
9),或在不存在的情况下首先创建新类别
const assignCategories = await prisma.post.create({
data: {
title: 'How to be Bob',
categories: {
create: [
{
assignedBy: 'Bob',
assignedAt: new Date(),
category: {
connectOrCreate: {
where: {
id: 9,
},
create: {
name: 'New Category',
id: 9,
},
},
},
},
],
},
},
})以下查询返回所有 Post 记录,其中至少一个(some)类别分配(categories)引用名为 "New category" 的类别
const getPosts = await prisma.post.findMany({
where: {
categories: {
some: {
category: {
name: 'New Category',
},
},
},
},
})以下查询返回所有类别,其中至少一个(some)相关的 Post 记录标题包含单词 "Cool stuff" 并且 该类别由 Bob 分配。
const getAssignments = await prisma.category.findMany({
where: {
posts: {
some: {
assignedBy: 'Bob',
post: {
title: {
contains: 'Cool stuff',
},
},
},
},
},
})以下查询获取所有类别分配(CategoriesOnPosts)记录,这些记录由 "Bob" 分配给 5 个帖子之一
const getAssignments = await prisma.categoriesOnPosts.findMany({
where: {
assignedBy: 'Bob',
post: {
id: {
in: [9, 4, 10, 12, 22],
},
},
},
})隐式多对多关系
隐式 m-n 关系将关系字段定义为关系两侧的列表。尽管关系表存在于底层数据库中,但它由 Prisma ORM 管理,不会在 Prisma 架构中显示。隐式关系表遵循特定约定。
隐式 m-n 关系使 m-n 关系的Prisma Client API变得更简单(因为在嵌套写入中嵌套的级别减少了一层)。
在下面的示例中,Post 和 Category 之间有一个隐式 m-n 关系
model Post {
id Int @id @default(autoincrement())
title String
categories Category[]
}
model Category {
id Int @id @default(autoincrement())
name String
posts Post[]
}查询隐式多对多
以下部分演示如何查询隐式 m-n关系。与显式 m-n 查询相比,这些查询需要的嵌套更少。
以下查询创建一条Post记录和多条Category记录
const createPostAndCategory = await prisma.post.create({
data: {
title: 'How to become a butterfly',
categories: {
create: [{ name: 'Magic' }, { name: 'Butterflies' }],
},
},
})以下查询创建一条Category记录和多条Post记录
const createCategoryAndPosts = await prisma.category.create({
data: {
name: 'Stories',
posts: {
create: [
{ title: 'That one time with the stuff' },
{ title: 'The story of planet Earth' },
],
},
},
})以下查询返回所有Post记录,并附带该帖子的已分配类别的列表
const getPostsAndCategories = await prisma.post.findMany({
include: {
categories: true,
},
})隐式 m-n 关系
- 对关系表使用特定约定
- 除非需要使用名称消除关系歧义,否则不要要求
@relation属性,例如@relation("MyRelation")或@relation(name: "MyRelation")。 - 如果你确实使用了
@relation属性,则无法使用references、fields、onUpdate或onDelete参数。这是因为这些参数对于隐式 m-n 关系来说取固定值,无法更改。 - 要求两个模型都有一个
@id。请注意- 你无法使用多字段 ID
- 你无法使用
@unique代替@id
提示
要使用这两个特性中的任何一个,你必须使用 显式的 m-n 关系。
隐式 m-n 关系中关系表的约定
如果你从 内省获得你的数据模型,你仍然可以通过遵循 Prisma ORM 的 关系表约定 来使用隐式 m-n 关系。以下示例假设你想要创建一个关系表来为名为 Post 和 Category 的两个模型获取一个隐式 m-n 关系。
如果你希望一个关系表被内省作为隐式 m-n 关系获取,则名称必须遵循此确切结构
- 它必须以下划线
_开头 - 然后按字母顺序排列的第一个模型的名称(在本例中为
Category) - 然后是关系(在本例中为
To) - 然后按字母顺序排列的第二个模型的名称(在本例中为
Post)
在示例中,正确的表名为 _CategoryToPost。
配置隐式多对多关系中关系表的名称
在使用 Prisma Migrate 时,你可以使用 @relation 属性配置由 Prisma ORM 管理的关系表的名称。例如,如果你希望关系表称为 _MyRelationTable,而不是默认名称 _CategoryToPost,你可以按如下方式指定它
model Post {
id Int @id @default(autoincrement())
categories Category[] @relation("MyRelationTable")
}
model Category {
id Int @id @default(autoincrement())
posts Post[] @relation("MyRelationTable")
}自关联
一对一自关系
model User {
id Int @id @default(autoincrement())
name String?
successorId Int? @unique
successor User? @relation("BlogOwnerHistory", fields: [successorId], references: [id])
predecessor User? @relation("BlogOwnerHistory")
}此关系表示以下内容
- “一个用户可以有一个或零个前任”(例如,Sarah 是 Mary 作为博客所有者的前任)
- “一个用户可以有一个或零个继任者”(例如,Mary 是 Sarah 作为博客所有者的继任者)
注意:一对一自关系不能在两边都设置为必需。一方或两方必须是可选的,否则将无法创建第一个
User记录。
创建一对一自关系
- 关系的双方都必须定义一个
@relation属性,该属性共享相同的名称 - 在本例中为 BlogOwnerHistory。 - 一个关系字段必须是 完全注释的。在此示例中,
successor字段定义了field和references参数。 - 一个关系字段必须由外键支持。
successor字段由外键successorId支持,该外键引用id字段中的值。successorId标量关系字段还需要一个@unique属性来保证一对一关系。
注意:一对一自关系需要两方,即使两方在关系中相等。例如,要对“最好的朋友”关系进行建模,你需要创建两个关系字段:
bestfriend1和bestfriend2。
无论哪一方由外键支持,Prisma Client 都会显示 predecessor 和 successor 字段
const x = await prisma.user.create({
data: {
name: "Bob McBob",
| successor: {
connect: {
id: 2,
},
},
| predecessor: {
connect: {
id: 4,
},
},
},
});一对多自关系
model User {
id Int @id @default(autoincrement())
name String?
teacherId Int?
teacher User? @relation("TeacherStudents", fields: [teacherId], references: [id])
students User[] @relation("TeacherStudents")
}此关系表示以下内容
- “一个用户有零个或一个老师”
- “一个用户可以有零个或多个学生”
请注意,您还可以通过将teacher字段设为必需来要求每个用户都有一个老师。
多对多自关联
model User {
id Int @id @default(autoincrement())
name String?
followedBy User[] @relation("UserFollows")
following User[] @relation("UserFollows")
}此关系表示以下内容
- “一个用户可以被零个或多个用户关注”
- “一个用户可以关注零个或多个用户”
请注意,对于关系数据库,这种多对多关系是隐式的。这意味着 Prisma ORM 在底层数据库中为其维护一个关系表。
如果您需要该关系保存其他字段,您也可以创建一个显式的多对多自关联。前面显示的自关联的显式版本如下所示
model User {
id Int @id @default(autoincrement())
name String?
followedBy Follows[] @relation("followedBy")
following Follows[] @relation("following")
}
model Follows {
followedBy User @relation("followedBy", fields: [followedById], references: [id])
followedById Int
following User @relation("following", fields: [followingId], references: [id])
followingId Int
@@id([followingId, followedById])
}在同一模型上定义多个自关联
您还可以在同一模型上一次定义多个自关联。以前面各节中的所有关系为例,您可以按如下方式定义一个User模型
model User {
id Int @id @default(autoincrement())
name String?
teacherId Int?
teacher User? @relation("TeacherStudents", fields: [teacherId], references: [id])
students User[] @relation("TeacherStudents")
followedBy User[] @relation("UserFollows")
following User[] @relation("UserFollows")
}引用操作
引用操作决定了当您的应用程序删除或更新相关记录时,记录将发生什么。
从 2.26.0 版本开始,您可以在 Prisma 模式中的关系字段上定义引用操作。这允许您在 Prisma ORM 级别定义级联删除和级联更新等引用操作。
在以下示例中,在 Post 模型上的 author 字段中添加 onDelete: Cascade 表示删除 User 记录也将删除所有相关的 Post 记录。
model Post {
id Int @id @default(autoincrement())
title String
author User @relation(fields: [authorId], references: [id], onDelete: Cascade)
authorId Int
}
model User {
id Int @id @default(autoincrement())
posts Post[]
}如果您未指定引用操作,则 Prisma ORM使用默认值。
引用操作默认值
如果您未指定引用操作,则 Prisma ORM 使用以下默认值
| 子句 | 可选关系 | 强制关系 |
|---|---|---|
onDelete | SetNull | Restrict |
onUpdate | Cascade | Cascade |
Cascade
onDelete: Cascade删除引用的记录将触发引用记录的删除。onUpdate: Cascade如果被依赖记录的引用标量字段被更新,则更新关系标量字段。
Restrict
onDelete: Restrict如果存在任何引用记录,则阻止删除。onUpdate: Restrict阻止更改引用记录的标识符。
SetNull
onDelete: SetNull引用对象的标量字段将设置为NULL。onUpdate: SetNull更新引用对象的标识符时,引用对象的标量字段将设置为NULL。
SetNull 仅适用于可选关系。在必需关系上,会抛出运行时错误,因为标量字段不能为 null。
SetDefault
onDelete: SetDefault引用对象的标量字段将设置为字段的默认值。onUpdate: SetDefault引用对象的标量字段将设置为字段的默认值。
索引
Prisma ORM 允许配置数据库索引、唯一约束和主键约束。这在版本 4.0.0 及更高版本中处于通用可用状态。您可以在版本 3.5.0 及更高版本中使用 extendedIndexes 预览功能启用此功能。
版本 3.6.0 还引入了对 MySQL 和 MongoDB 中全文索引的内省和迁移的支持,方法是通过一个新的 @@fulltext 属性,可通过 fullTextIndex 预览功能获得。
数据库映射
该 Prisma 模式 包含允许您定义某些数据库对象名称的机制。您可以
映射集合/表和字段/列名称
有时,用于描述数据库中实体的名称可能与您在生成的 API 中的首选名称不匹配。在 Prisma 模式中映射名称允许您影响 Client API 中的命名,而无需更改底层数据库名称。
@map 和 @@map 允许您通过将模型和字段名称与底层数据库中的表和列名称解耦来 调整 Prisma Client API 的形状。
model Comment {
// Fields
@@map("comments")
}使用此修改后的模型定义,Prisma Client 会自动将 Comment 模型映射到底层数据库中的 comments 表。
映射字段/列名称
model Comment {
content String @map("comment_text")
email String @map("commenter_email")
type Enum @map("comment_type")
@@map("comments")
}这样,comment_text 列在 Prisma Client API 中不可用于 prisma.comment.comment_text,但可以通过 prisma.comment.content 访问。
映射枚举名称和值
enum Type {
Blog,
Twitter @map("comment_twitter")
@@map("comment_source_enum")
}约束和索引名称
您可以选择使用 map 参数在 Prisma 模式中为属性 @id、@@id、@unique、@@unique、@@index 和 @relation 明确定义底层约束和索引名称。
使用自定义约束/索引名称
您可以使用 map 参数在底层数据库中定义自定义约束和索引名称。
model User {
id Int @id(map: "Custom_Primary_Key_Constraint_Name") @default(autoincrement())
name String @unique
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
authorName String @default("Anonymous")
author User? @relation(fields: [authorName], references: [name])
@@index([title, authorName], map: "My_Custom_Index_Name")
}内省
您可以使用 Prisma CLI 对您的数据库进行内省,以便在您的 数据模型 中生成 Prisma 模式。数据模型是 生成 Prisma Client 所必需的。
当 将 Prisma ORM 添加到现有项目 时,内省通常用于生成数据模型的初始版本。
但是,它也可以 在应用程序中重复使用。当您不使用 Prisma Migrate 而是使用纯 SQL 或其他迁移工具执行模式迁移时,最常见的情况就是这样。在这种情况下,您还需要重新内省您的数据库并随后
内省的作用是什么?
内省有一个主要功能:使用反映当前数据库模式的数据模型填充您的 Prisma 模式。
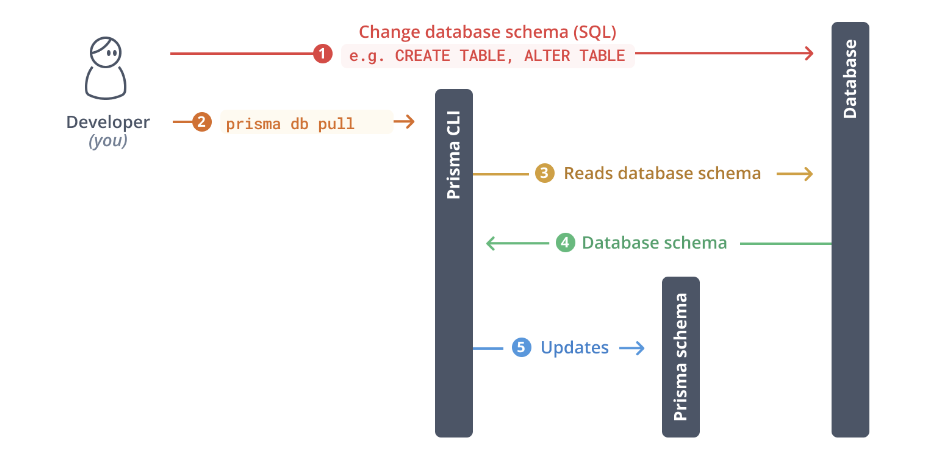
prisma db pull 命令
您可以使用 Prisma CLI 的 prisma db pull 命令对您的数据库进行内省。请注意,使用此命令需要在您的 Prisma 模式 datasource 中设置您的 连接 URL。
以下是 prisma db pull 在内部执行的步骤的高级概述
- 从 Prisma 模式中的
datasource配置读取 连接 URL - 打开与数据库的连接
- 内省数据库模式(即读取表、列和其他结构...)
- 将数据库模式转换为 Prisma 模式数据模型
- 将数据模型写入 Prisma 模式或 更新现有模式
内省工作流程
对于不使用 Prisma Migrate 而是使用纯 SQL 或其他迁移工具的项目,典型的工作流程如下所示
- 更改数据库模式(例如,使用纯 SQL)
- 运行
prisma db pull以更新 Prisma 模式 - 运行
prisma generate以更新 Prisma Client - 在您的应用程序中使用更新的 Prisma Client
属性顺序
内省按以下顺序添加属性(此顺序由 prisma format 镜像)
- 块级:
@@id、@@unique、@@index、@@map - 字段级:
@id、@unique、@default、@updatedAt、@map、@relation